CVG 1.9.0 (29-Mar-2021)
This release 1.9.0 of CVG is all about health monitoring and even more flexibility when using Speech-To-Text Engines.
Now more information about the health status of a CVG project is visible in the console (UI), making troubleshooting easier during operation and when starting a project. CVG had previously only made this data available to our customers’ monitoring systems via the Health API.
In order to recognize the user’s speech input optimally depending on the situation, it is now possible to switch the speech-to-text engine during a dialog.
Project Health visualised in UI
The redesigned project dashboard (replacing settings as the default tab) visualizes data from our Health API:
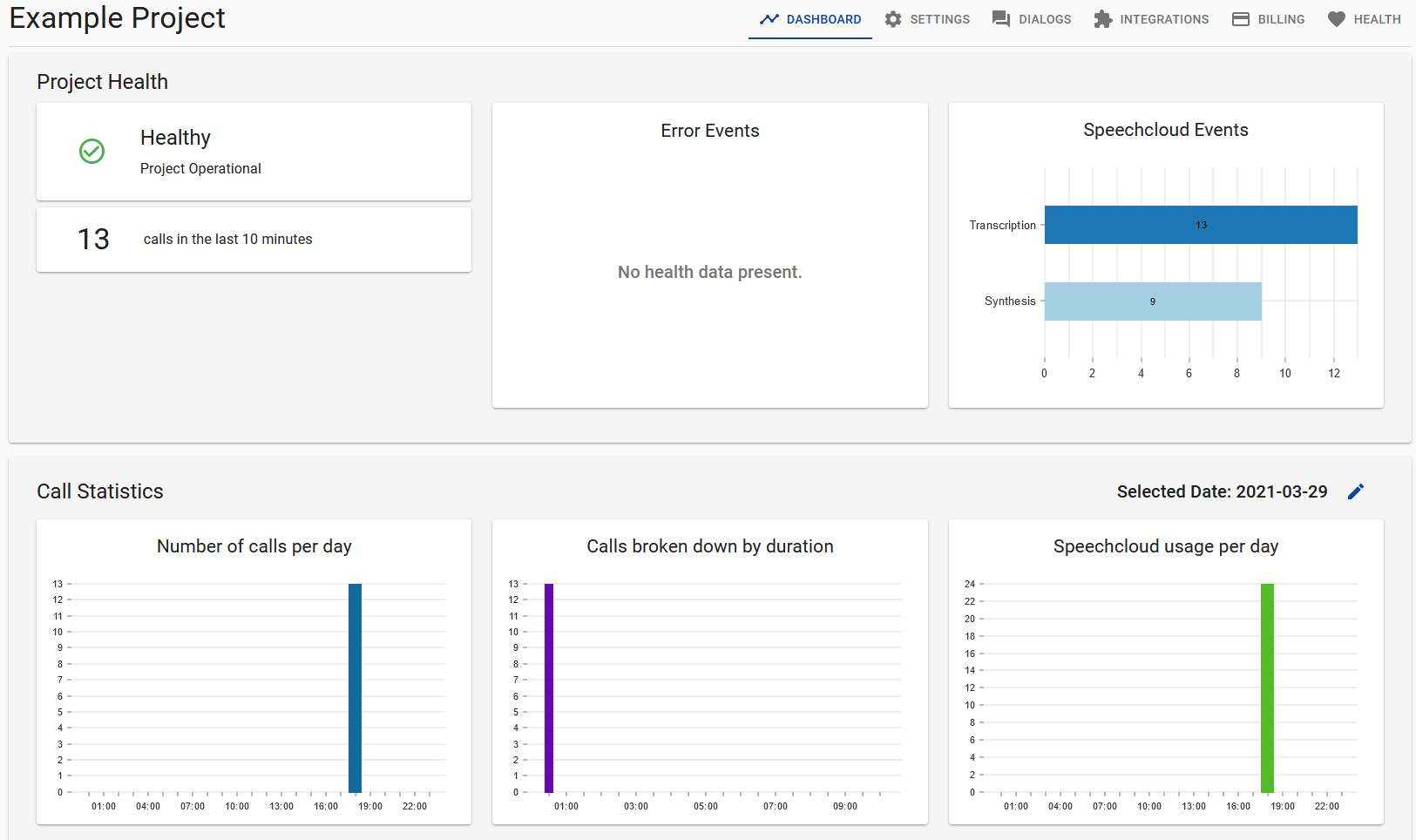
There is also a new dedicated health tab, which shows further details for any the health events that occurred in the last 10 minutes. For instance, a failed /session call might look like this:
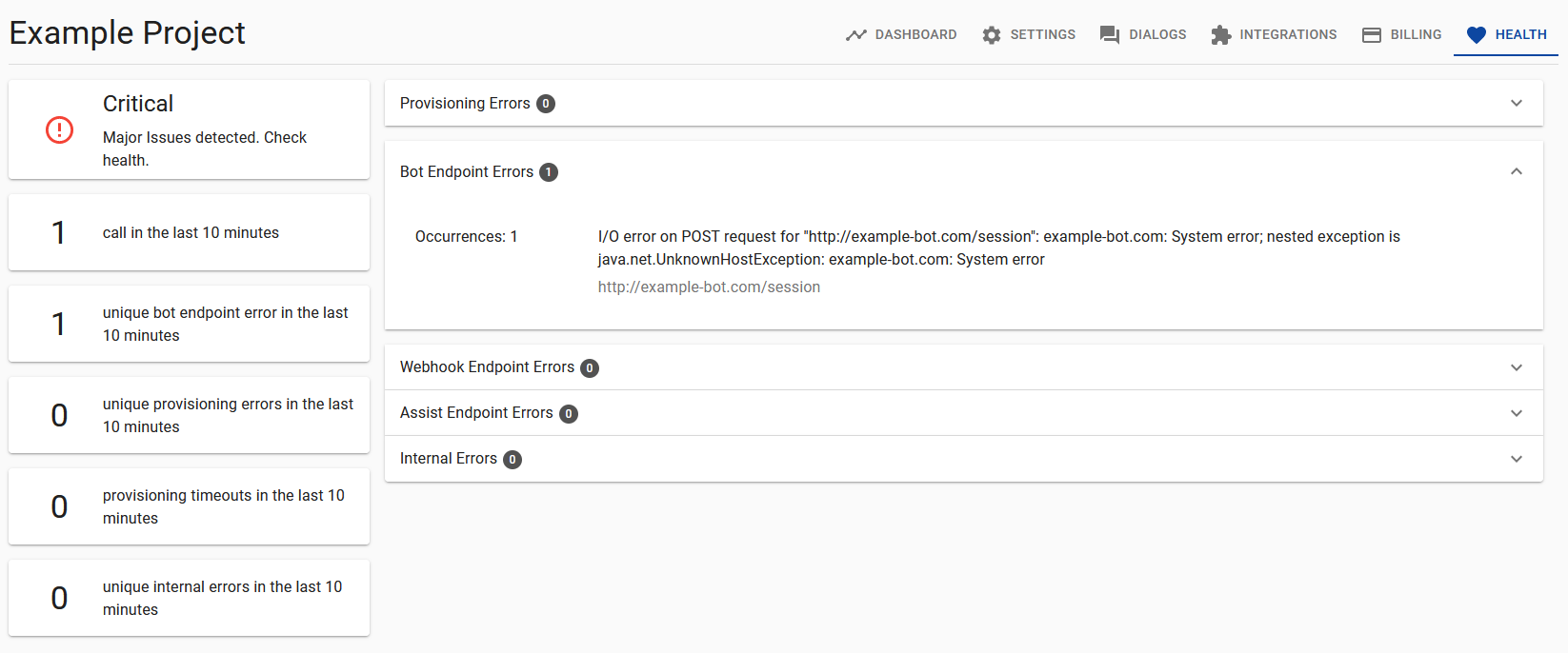
This data can also be retrieved from our Health API endpoint events.
Health API Endpoint Events
CVG has three “client APIs” that call endpoints on the customer side:
When invoking an endpoint, multiple things could go wrong that can be tricky to debug:
the URL could be incorrect or temporarily unreachable
the server could return an error response like HTTP 500
Prior to this release, our Health API only included error details for Bot API calls. With the introduction of two new AssistEndpointCallFailed and WebhookCallFailed health events, all three client APIs are now covered.
The new events are also visible in our new Project Health UI.
Switch Transcription Engine during Dialog
One of CVG’s strengths is the ability to select the transcriber and synthesizer engines that best fit your specific use case.
This release introduces a new /call/transcription/switch endpoint to the call API. With /call/transcription/switch you can even switch to another transcription provider/profile and/or language in the middle of the dialog. For synthesis, the use of different vendors and languages in a dialog was already possible before with the synthesizers and language parameters in /say and /prompt.
Usage example of /call/transcription/switch:
{
"dialogId": "b3293e28-a442-4c75-be13-756a6477af4c",
"transcribers": ["MICROSOFT"],
"language": "en-US"
}
As usual, the transcribers parameter is a list in order to support fallbacks, and also accepts speech cloud profiles ("MICROSOFT-profile"). If the transcribers or language parameter is missing, it will fall back to what’s configured in the project. As a result, you can omit both to reset transcription back to the project settings.
Potential use cases for this API include:
You want to ask the caller a question where you know a particular transcription engine will likely understand the answer better, and then switch back to the engine configured in the project.
You’re developing a multilingual bot that can dynamically switch to a different language based on user input.
Google Streaming Speech-to-Text Transcription
Do you want to reduce delay on speech transcription? Try out the Streaming Speech Recognition of Google Speech-to-Text. To do so select “Google - Streaming Transcription” as Transcriber Engine for your project in CVG console.
With Streaming Speech Recognition, CVG streams the caller’s real-time audio to Google throughout the duration of the call. This is also referred to as “endless streaming transcription.” Speech-to-Text results are provided in near real-time as the audio is processed.
In comparison, the default Google transcriber (”Google (Default)”) means that CVG itself recognizes the beginning and end of an utterance in the audio and only sends this utterance as an audio snippet to Google for transcription. So here we are more flexible, e.g. when defining the end of an utterance.
In our test cases it’s not always that Google Streaming Speech-to-Text is faster than Google (Default). We would really love to hear what your experience is like.
Smaller API Improvements
Project Context in Bot API
Every endpoint in the Bot API now has an additional projectContext, which is an object with two fields:
{
"projectContext": {
"projectToken": "976f8e84-8f88-4d2f-ac26-842d70082e53",
"resellerToken": "580e0b32-826a-4984-be33-b56dd7b36d11"
},
...
}
This can be useful for invoking other APIs that require these tokens such as the Dialog or Health APIs, without needing to hardcode them on your end.
Update to Recording Transcript Format
Version 1.7.0 introduced the Recording API which also creates a transcript of each recording. While the format is already part of our public API, it is still subject to change while we are collecting feedback and evaluating new use-cases.
With this release we have overhauled the structure of the transcript to model the the content of the recording more closely. The first version only contained one kind of entry which contained text and optionally a confidence.
The new model now differenatiates between four kinds of entries:
Voice: These entries are produced by transcribing voice from a human.
Text: These entries are produced by a bot (using the
/call/sayendpoint usually).Audio: These entries are produced by audio playback using the
/call/playendpoint.Dtmf: These entries are produced by typing on the keypad.
For details please check out the Recording API.
We ❤️ to receive your feedback.